
Domain Types: The architecture your subdomain deserves (Part 4)
Applying the same architecture everywhere often leads to overengineering, underengineering, or both. Discover how domain types can help you choose the right level of architectural complexity.
This article is part of the Strategic Domain-Driven Design: Domain Types series:
1. Domain Types: Identifying core, supporting, and generic domains (Part 1)
2. Domain Types: Build, buy, or outsource? (Part 2)
3. Domain Types: What if you build nothing? (Part 3)
4. Domain Types: The architecture your subdomain deserves (Part 4)
We classify domains not for the sake of classification itself. As you already learned, this classification can help you decide whether a domain should be built internally, outsourced, or bought.
Today, we will look at this classification from a different perspective and learn how it can support architectural decisions regarding the code that solves problems within these areas.
Code architecture and the system
Nowadays, most systems contain several subdomains. Even if you are building a monolith, it is definitely better for you and your fellow engineers to keep solutions for similar problems within well-defined boundaries (a modular monolith). If you work with microservices, this naturally leads to clear boundaries within the system.
With that in mind, do not blindly apply the same code structure everywhere. There is no perfect architecture for every situation. Even though this may sound like a cliché, considering how many teams still build their systems, it is worth repeating.
Once you understand this principle, do not forget it when designing your system. Using the same architecture everywhere (layered, ports and adapters, or any other approach) usually means that you are either overengineering or underengineering certain parts of the system. In many cases, you may end up doing both.
Why is that?
Because protecting the structure of the code comes with a cost: time, effort, and knowledge. Sometimes that cost is low, and sometimes it is significant. That is why you should consciously decide whether a particular investment is worth making.
It is rarely worth introducing dozens of layers to isolate logic when all you are doing is integrating with a third-party library.
On the other hand, you would not want to keep REST APIs, models, database configuration, and business logic in a single folder when that code is responsible for a crucial part of the business.
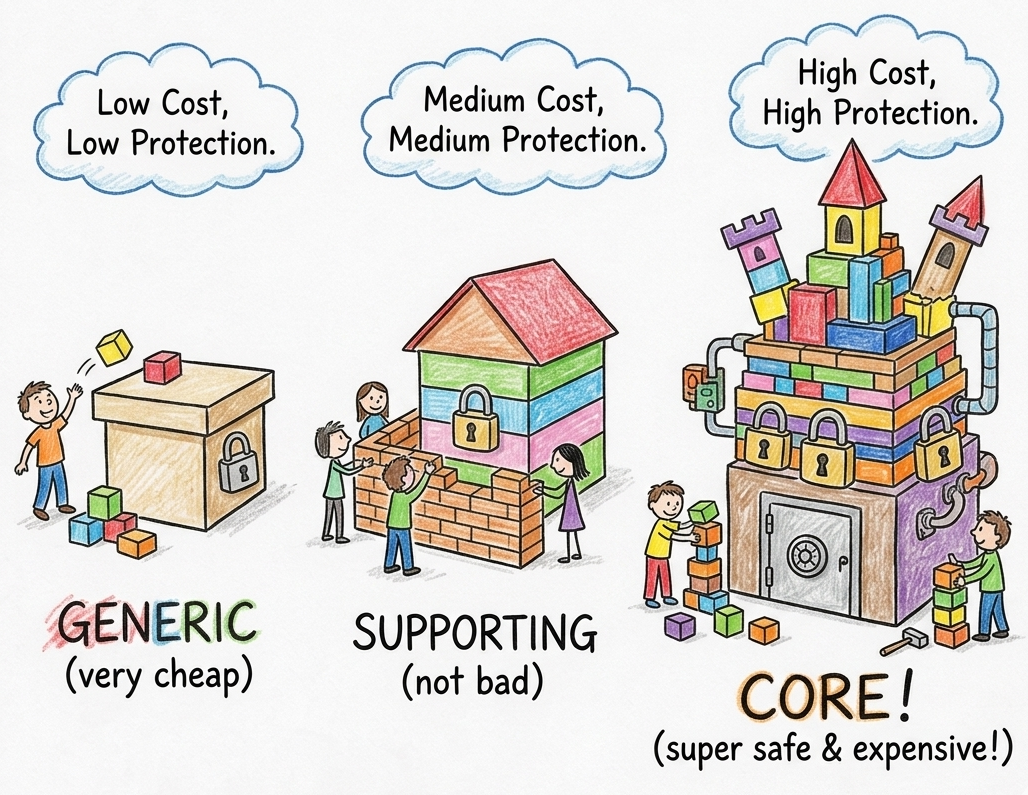
Cost vs. protection
There are many dimensions through which you can evaluate a code structure. For us, two are particularly important because they are directly related and usually move together (for example, both low or both high):
- Cost of maintenance – the less complex the code structure is and the fewer constraints and rules you need to follow, the less effort is required to preserve the code architecture over time. Imagine a single directory where everything is placed, with no naming conventions or established patterns. There is almost no maintenance cost because you simply put everything in one place and implement it however you like. At the other extreme, you may have an architecture that enforces communication through commands, events, and DTOs while heavily relying on layers and interfaces. The maintenance cost is significantly higher because many rules and conventions must be followed.
- Level of domain protection – the most important part of the software is the code responsible for implementing domain requirements. This part is unique to the system. Different architectures provide different levels of protection for that code. Sometimes the protection is strong, and sometimes it barely exists. Imagine a situation where the domain model and business rules are isolated from frameworks and libraries. Then compare it to a solution where business logic is scattered across controllers, services, and handlers, mixed with caching, HTTP integrations, and infrastructure concerns. The first approach makes business rules easier to find, understand, and modify in a low-risk manner.
Subdomains and the right choice
When we look at these two dimensions through the lens of domain types, they become useful guidance for selecting an appropriate code architecture:
- generic subdomains - low cost (and therefore low protection)
- supporting subdomains - medium cost and medium protection
- core domains - high protection (and therefore high cost)
Let me explain why.
Generic subdomains
These are places where you mostly rely on third-party services or libraries and where most of the work is integration. There is usually little code, little complexity, and few business rules, if any. On top of that, these areas rarely change after the initial implementation.
You want to keep the cost as low as possible. A low level of domain protection is acceptable because there is little or no domain knowledge to protect. Much of the code created here can be easily found online or generated by an AI assistant with minimal guidance.
Core domains
Here you will find a large number of business rules. Since these areas are where the company builds its competitive advantage, continuous evolution is expected.
Strong domain isolation is highly beneficial. It makes future development, testing, and modifications easier and safer. Keeping the domain separated also makes it easier to understand, revisit, and continuously refactor.
Because these areas provide significant business value, investing in an architecture with a higher maintenance cost is a trade-off worth making. The long-term benefits outweigh the additional cost.
Supporting subdomains
Here, balance is the key. We do not know how much complexity will emerge over time, but we know these areas are not strategically critical.
It is worth providing some degree of protection, but not at any cost. This approach keeps the system open for future evolution while maintaining a reasonable level of architectural overhead.
Subdomains and code architecture
Since we understand the relationship between cost and domain protection, and we know how it applies to different subdomain types, the final question remains: Which architecture should we choose?
I recommend the following:
- Generic subdomains (low cost, low protection) – an implementation-oriented structure, such as a single package/folder or packages organized around implementation concerns (controllers, services, DTOs, etc.). The solution should involve few rules and require little architectural experience to maintain.
- Supporting subdomains (medium cost, medium protection) – layered architecture. This introduces a reasonable level of domain isolation without excessive abstraction. It is also widely understood by engineers and requires little additional learning.
- Core domains (high protection, high cost) – one of the ports and adapters architectures (Hexagonal, Onion, or Clean Architecture). The domain is strongly isolated and protected. Of course, the cost includes additional ports, adapters, DTOs, and layers that need to be maintained. These approaches are also more difficult to understand and follow, which increases the learning curve.
Let's look at the Training Centre
Let's take a look at the Training Centre and the subdomains we identified.
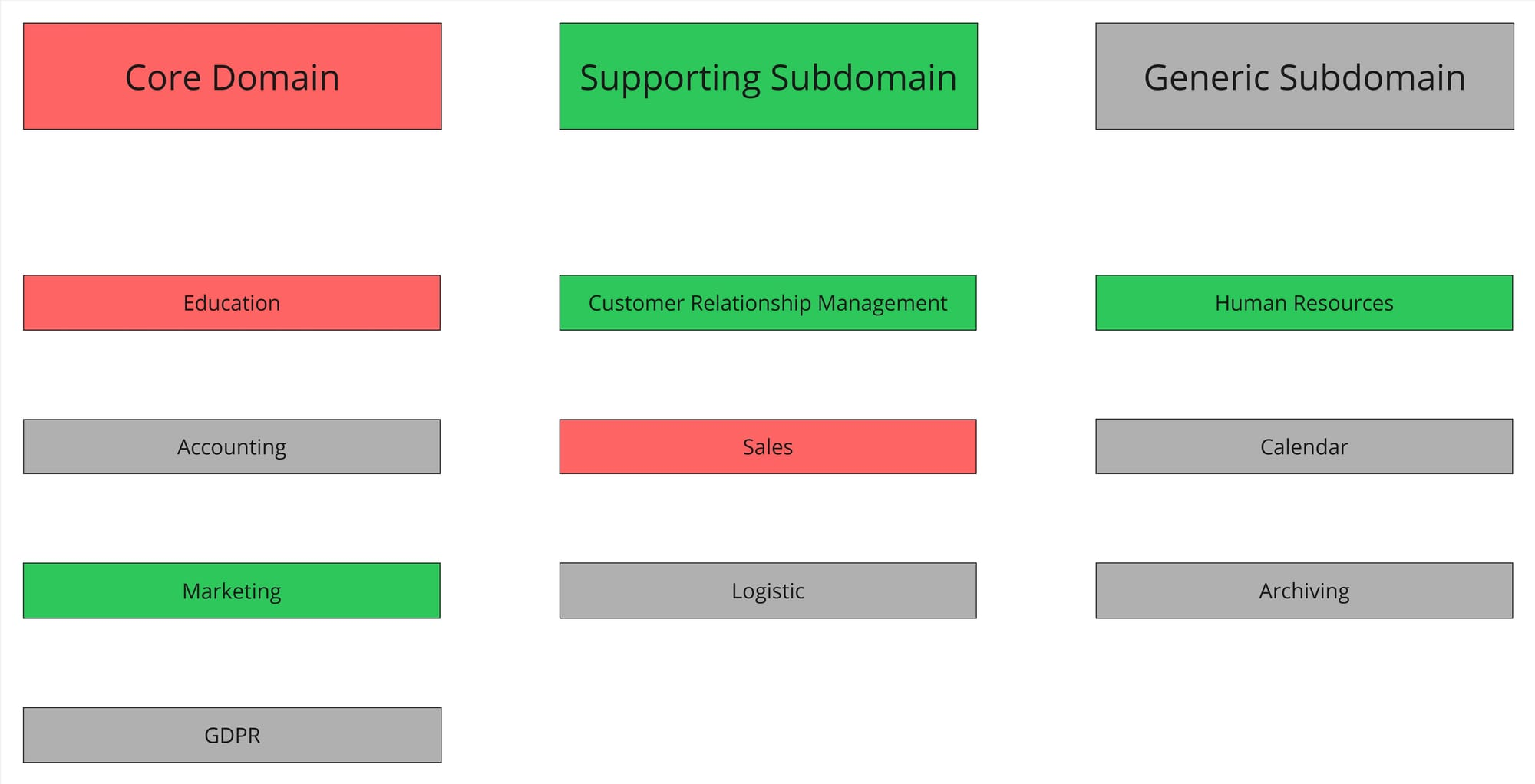
The decisions we made lead to the following architectural recommendations:
- ports and adapters for Education and Sales
- layered architecture for CRM, HR, and Marketing
- implementation-oriented structure for Accounting, Calendar, Logistics, Archiving, and GDPR
Summary
Domain types are not only useful for discovering the problem space and reflecting it in the solution space. They also help determine where architectural investment is justified and where a simpler implementation-oriented structure is the better choice.
This perspective can guide technical decisions and help ensure that architectural choices are driven by actual business needs, expected evolution, and future challenges.
Continue the Strategic Domain-Driven Design: Domain Types series: [Previous]


Comments ()